1.简单介绍
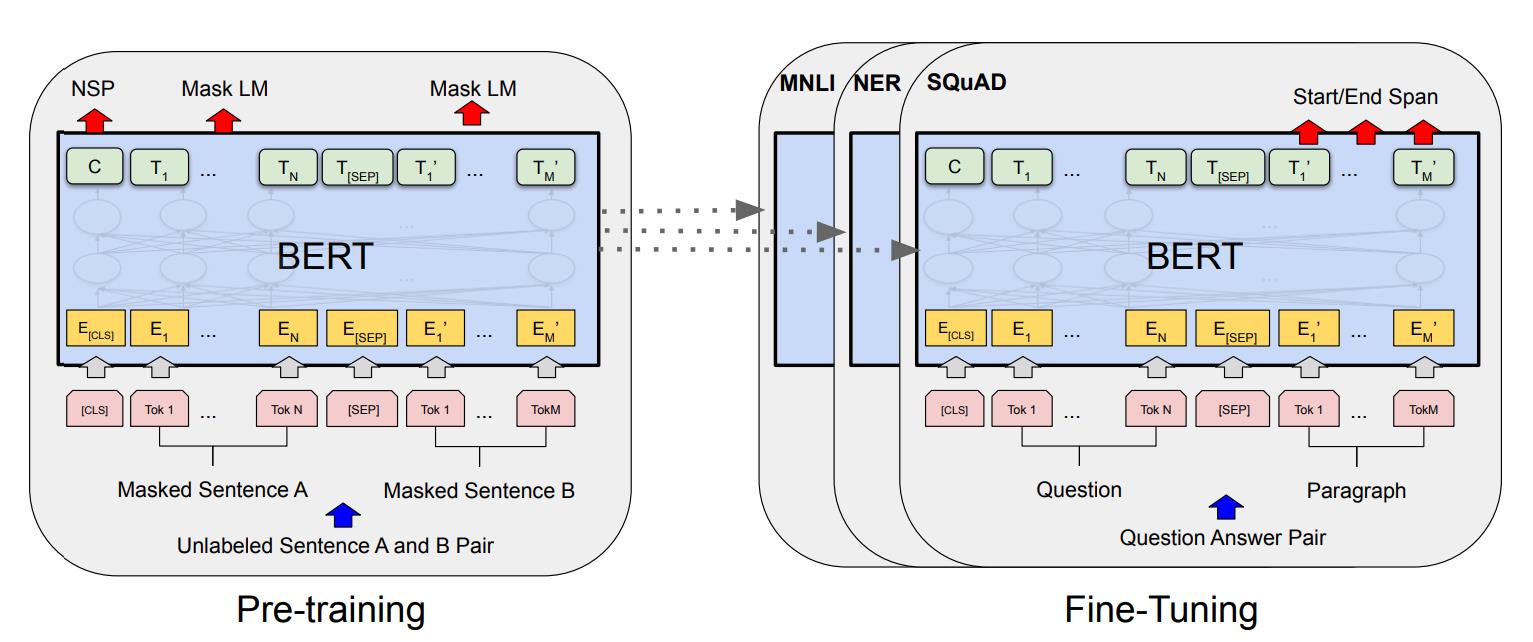
BERT (Bidirectional Encoder Representation Transformers) 是在2018年由Google AI 团队发布的,网络结构主要采用了Transformer编码器的架构,属于自编码模型。具体而言,BERT是一个多层Transformer的Encoder,输入的Embedding通过一层层的Encoder进行编码转换,再连接到不同的下游任务。
2. 算法原理
2.1 模型输入
总体来说,Bert网络结构与Transformer Encoder结构基本相同,
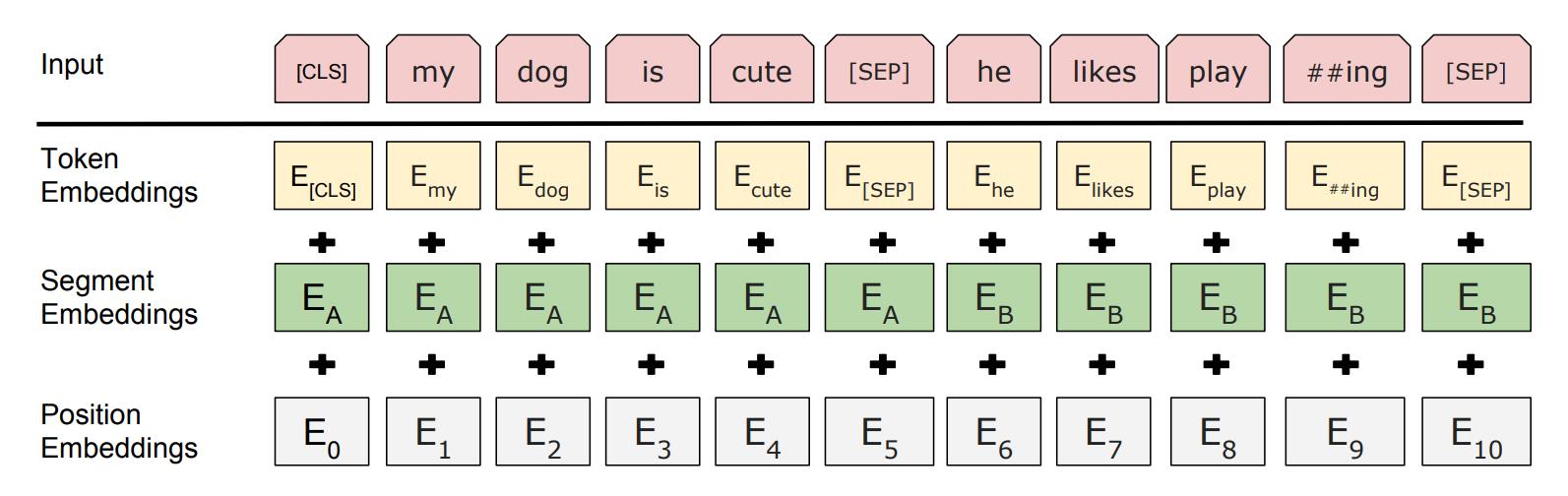
其输入向量由三部分组成,分别是token embedding, segment embedding和position Embedding。在分词接入token embedding之前,先进行tokenization处理。这里采用WordPiece嵌入方式,将每个单词进一步拆分成更通用的sub-word,可以避免词汇表过大及减缓OOV的问题。这里position Embedding与transformer实现不同,是通过网络学习得到的。
2.2 预训练任务
BERT采用两个无监督任务进行参数预训练:
- MLM(Masked Language Model): 对句子中的word随机mask,让模型去预测mask掉的单词。在BERT的预训练中采取的策略是随机抽取句子中15%的单词进行处理,其中这15%的单词又按照80%-10%-10%的比例采取不同的处理方式:80%的单词用[MASK]来替换,表示需要预测的部分,10%用随机的词来替换,10%维持原单词不变。这种训练流程可以让模型学习到单词在上下文中的分布表示;
- NSP(Next Sentence Prediction): 对于句子对A和B,选取B的时候50%的概率是真实的A的下一句(标签IsNext),50%的概率是从语料中随机选取的句子(标签NotNext)。通过预训练NSP任务,让模型理解到两个句子之间的关系,从而能够应用于QA和NLI等下游任务中。
2.3 预训练数据和参数
以下分项列出BERT预训练过程使用的所有数据和调试参数:
- 数据集:BooksCorpus (单词量 800M),English Wikipedia (单词量 2,500M)
- 主要超参:batch_size=256, epochs=40, max_tokens=512, dropout=0.1
- 优化器参数:优化器Adam, lr=1e-4, β1=0.9, β2=0.999, L2 weight decay=0.01, lr_warmup=10,000
- 激活函数:gelu
- 训练损失:mean MLM likelihood + mean NSP likelihood
机器配置:BERT(base)使用4个云TPUs,BERT(large)使用16个云TPUs - 训练时长:4天
- 加速方式:90%的步数按照128的文本长度训练,剩余10%的步数按照512的文本长度训练
2.4 BERT的下游任务
特定任务的模型是通过在BERT基础上增加一个额外的输出层,BERT典型的四个下游任务分别是:
- 句子对分类任务:如MNLI, QQP, QNLI, STS-B, MRPC, RTE, SWAG任务;
- 单句子分类任务:如SST-2,CoLA任务;
- 问答系统任务:如SQuAD v1.1任务;
- 单句子标注任务:如CoNLL-2003 NER任务;

3. 加载模型
由于从头训练大模型需要耗费大量数据和算力,我们可以从HuggingFace中下载其他公司已经训练好的Bert模型来使用。
这里简单介绍torch及transformers库加载bert模型,代码如下:
from transformers import BertModel
bert = BertModel.from_pretrained("pre_model/bert-base-chinese")
print(bert)
模型输入,查看源码可以看到BertModel的forward函数
def forward(
self,
input_ids: Optional[torch.Tensor] = None,
attention_mask: Optional[torch.Tensor] = None,
token_type_ids: Optional[torch.Tensor] = None,
position_ids: Optional[torch.Tensor] = None,
head_mask: Optional[torch.Tensor] = None,
inputs_embeds: Optional[torch.Tensor] = None,
encoder_hidden_states: Optional[torch.Tensor] = None,
encoder_attention_mask: Optional[torch.Tensor] = None,
past_key_values: Optional[List[torch.FloatTensor]] = None,
use_cache: Optional[bool] = None,
output_attentions: Optional[bool] = None,
output_hidden_states: Optional[bool] = None,
return_dict: Optional[bool] = None,
) -> Union[Tuple[torch.Tensor], BaseModelOutputWithPoolingAndCrossAttentions]:关键参数介绍:
- input_ids (torch.LongTensor of shape (batch_size, sequence_length)) — 词汇表中输入序列标记的索引
- attention_mask (torch.FloatTensor of shape (batch_size, sequence_length), optional) — 对输入数据进行mask,解决pad问题。在 [0, 1] 中选择的掩码值:1 表示未屏蔽的标记,0 表示已屏蔽的标记
- token_type_ids (torch.LongTensor of shape (batch_size, sequence_length), optional) — 分段标记索引以指示输入的第一和第二部分。在 [0, 1] 中选择索引:0对应一个句子A的token,1对应一个句子B的token。
模型输入我们可以自己构建,也可以利用Transformers中的分词器对象构建,操作如下:
from transformers import BertModel, BertTokenizer
tokenizer = BertTokenizer.from_pretrained("pre_model/bert-base-chinese")
test_sentence = "我在测试bert"
tokens = tokenizer.encode_plus(text=test_sentence)
print(tokens)
print(tokenizer.convert_ids_to_tokens(tokens['input_ids']))输出结果如下:
{'input_ids': [101, 2769, 1762, 3844, 6407, 8815, 8716, 102],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1]}
['[CLS]', '我', '在', '测', '试', 'be', '##rt', '[SEP]']
可以看到该方法就已经对输入的句子进行了分词,需要提醒的是:这里的tokenizer分词不同以往的分词方法,使用subword算法(词”bert”就被分开了),并且为语句的句首和句首分别添加了[CLS]、[SEG]符号。
模型使用案例:
from transformers import BertModel, BertTokenizer
bert = BertModel.from_pretrained("pre_model/bert-base-chinese")
tokenizer = BertTokenizer.from_pretrained("pre_model/bert-base-chinese")
test_sentence = "我在测试bert"
# 指定返回的数据是pytorch中的tensor数据类型
tokens = tokenizer.encode_plus(text=test_sentence, return_tensors='pt')
model_out = bert(**tokens)
print(model_out) # model_out是BaseModelOutputWithPoolingAndCrossAttentions对象模型默认的输出BaseModelOutputWithPoolingAndCrossAttentions对象,可以看到源码中forward函数的返回值输出:
return BaseModelOutputWithPoolingAndCrossAttentions(
last_hidden_state=sequence_output,
pooler_output=pooled_output,
past_key_values=encoder_outputs.past_key_values,
hidden_states=encoder_outputs.hidden_states,
attentions=encoder_outputs.attentions,
cross_attentions=encoder_outputs.cross_attentions,
)
# BaseModelOutputWithPoolingAndCrossAttentions中各参数类型
(last_hidden_state: FloatTensor = None,
pooler_output: FloatTensor = None,
hidden_states: typing.Optional[typing.Tuple[torch.FloatTensor]] = None,
past_key_values: typing.Optional[typing.Tuple[typing.Tuple[torch.FloatTensor]]] = None,
attentions: typing.Optional[typing.Tuple[torch.FloatTensor]] = None,
cross_attentions: typing.Optional[typing.Tuple[torch.FloatTensor]] = None)我们经常使用的则是:
last_hidden_state (torch.FloatTensor of shape (batch_size, sequence_length, hidden_size)) — 模型最后一层输出的隐藏状态序列.
pooler_output (torch.FloatTensor of shape (batch_size, hidden_size))— 是模型last_hidden_state选取[CLS]位置对应的向量经过一个线性层+tanh()激活函数之后得到的
hidden_states (tuple(torch.FloatTensor), optional, returned when output_hidden_states=True is passed or when config.output_hidden_states=True) — 形状为(batch_size, sequence_length, hidden_size)的torch.FloatTensor 构成的元组(embedding层 + 每一个transformer encoder的输出),例如bert一般12层,因此该tuple长度为13.
hidden_states[-1]就是last_hidden_state



